
Thread Synchronization in C

I don’t write for absolute beginners so this post is for someone who know on a high level how threads work but does not know the low levels
some facts on threads first
A thread is the smallest unit of execution that a CPU can schedule and run
A process can have one or more threads; they share the same memory space but run independently
Each thread has its own stack (function calls, local variables) but shares heap, globals, and resources with other threads of the same process
Threads let multiple tasks run seemingly at the same time within a single program
Concurrency comes from starting multiple threads so that while one is waiting (for I/O, lock, etc.), another can use the CPU
On multi-core CPUs, different threads can actually run in parallel on different cores
The downside: since threads share memory, you must use synchronization (locks, semaphores, etc.) to prevent data corruption when multiple threads access the same data
the last point of what this whole article is going to be about. so lets lock-in 💪
Race Condition
Consider a simple, common operation: incrementing a shared counter. This appears atomic at a high level, but at the machine instruction level, it's typically a sequence of three distinct operations:
Read: Load the current value of the counter into a CPU register.
Modify: Increment the value in the register.
Write: Store the new value from the register back into memory.
Now, imagine two threads, Thread A and Thread B, both attempting to increment the same shared integer counter which is initially 0.
Scenario 1: Desired Outcome (Sequential Execution)
Thread A:
Reads counter (value is 0)
Increments register (register value is 1)
Writes register to counter (counter is now 1)
Thread B:
Reads counter (value is 1)
Increments register (register value is 2)
Writes register to counter (counter is now 2)
Final counter value: 2. This is correct.
Scenario 2: Race Condition Leading to Incorrect Outcome
Thread A: Reads counter (value is 0). Context switch.
Thread B:
Reads counter (value is 0)
Increments register (register value is 1)
Writes register to counter (counter is now 1). Context switch.
Thread A:
Increments register (register value, which was 0 from its initial read, becomes 1)
Writes register to counter (counter is now 1).
Final counter value: 1. This is incorrect. Both threads executed their increment operation, but the shared counter only reflects one increment because Thread A overwrote Thread B's update with an outdated value. This is a classic example of a "lost update."
#include <stdio.h>
#include <pthread.h>
int shared_counter = 0;
void* increment_function(void* arg) {
int num_iterations = *((int*)arg);
for (int i = 0; i < num_iterations; i++) {
shared_counter = shared_counter + 1;
}
return NULL;
}
int main() {
pthread_t thread1, thread2;
int iterations_per_thread = 100000;
pthread_create(&thread1, NULL, increment_function, &iterations_per_thread);
pthread_create(&thread2, NULL, increment_function, &iterations_per_thread);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
printf("Expected: %d\n", 2 * iterations_per_thread);
printf("Actual: %d\n", shared_counter);
return 0;
}Atomicity
From the perspective of any other thread, an atomic operation is either not yet started or fully complete—there is no observable intermediate state.
As we saw, the C statement shared_counter = shared_counter + 1; is not atomic. It is composed of multiple machine instructions (read, modify, write). A race condition occurs precisely because a thread can be preempted in the middle of this non-atomic sequence.
If we could make that increment operation atomic, the race condition would disappear.
How is Atomicity Achieved?
Hardware Support: Modern CPUs provide special atomic instructions. These instructions are guaranteed by the hardware to execute without being interrupted. Common examples include:
Test-and-Set: Atomically writes a value to a memory location and returns its old value.
Fetch-and-Add: Atomically increments a value in memory and returns the old value.
Compare-and-Swap (CAS): Atomically compares the contents of a memory location to a given value and, only if they are the same, modifies the contents of that memory location to a new given value. This is a cornerstone of many advanced lock-free algorithms.
In C, using the <stdatomic.h> header (since C11), you can perform these operations. For example, atomic_fetch_add(&shared_atomic_counter, 1); would perform a hardware-guaranteed atomic increment.
Software Implementation (via Locks): The more common way to achieve atomicity for a sequence of operations is by using synchronization primitives. By placing a lock before a sequence of instructions (the critical section) and releasing it after, we create a block of code that is effectively atomic from the perspective of other threads.
CPU Level Reordering
// Shared global variables
int data = 0;
int is_ready = 0;
// Thread 1 (Producer)
void producer() {
data = 42; // Write 1
is_ready = 1; // Write 2
}
// Thread 2 (Consumer)
void consumer() {
if (is_ready == 1) { // Read 1
// The programmer expects that if is_ready is 1,
// then the write to 'data' must have happened first.
printf("Data is %d\n", data); // Read 2
}
}On a weakly-ordered system, it is possible for the CPU or compiler to reorder the writes in producer. The is_ready = 1 write might become globally visible to the consumer thread before the data = 42 write does. The consumer would then read is_ready == 1, proceed, and print "Data is 0". This is a subtle but critical form of race condition caused by memory reordering.
Axiom 1: Private Caches
Each CPU core has its own private L1/L2 cache.
A write operation by a thread on Core A updates Core A's private cache first.
This write is not instantly visible to a thread on Core B. It becomes visible only after the cache coherence protocol propagates the change. This propagation is not instantaneous.
Axiom 2: Store Buffers
To avoid stalling on slow memory writes, each core has a "store buffer." When a thread performs a write, the data is often placed in this buffer first. The CPU can then continue executing other instructions while the memory system works on committing the buffered write to the cache in the background.
A write sitting in Core A's store buffer is completely invisible to Core B.
Axiom 3: Instruction Reordering
To maximize performance, the compiler and the CPU are permitted to reorder instructions.
Rule 3a (Load/Load and Store/Store Reordering): Weak architectures (like ARM) can reorder two read operations or two write operations. Stronger architectures (like x86) generally do not reorder writes with other writes.
Rule 3b (Store/Load Reordering): Nearly all architectures (including x86) allow a write to be reordered with a subsequent, independent read. This is the most common and problematic source of reordering. The CPU can speculatively execute a read before a preceding write has been fully committed from its store buffer.
Axiom 4: The Programmer's View vs. Reality
The order of instructions in your C code is merely a suggestion to the machine.
The final order of execution is a complex combination of compiler reordering and CPU runtime reordering, governed by the axioms above.
With these axioms, let's analyze the execution flow.
Execution Flow: WITHOUT Locks
Shared Data:
int data = 0;
int is_ready = 0;
Producer Code (Thread P on Core A):
data = 42;
is_ready = 1;
Consumer Code (Thread C on Core B):
if (is_ready == 1)
print(data);
Let's trace a possible, and perfectly valid, sequence of events according to our axioms.
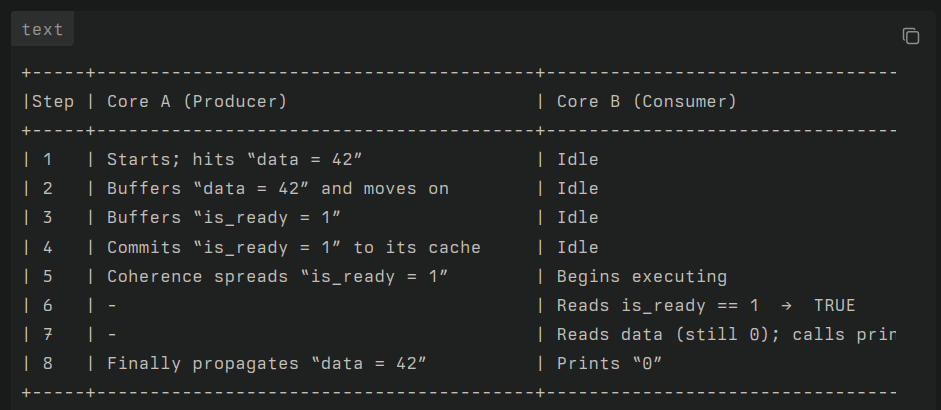
This scenario demonstrates a producer-side reordering problem, made possible by the Store Buffer (Axiom 2). A similar scenario could be constructed for a consumer-side reordering (Axiom 3b) where the consumer reads data before it reads is_ready. The result is the same: incorrect behavior.
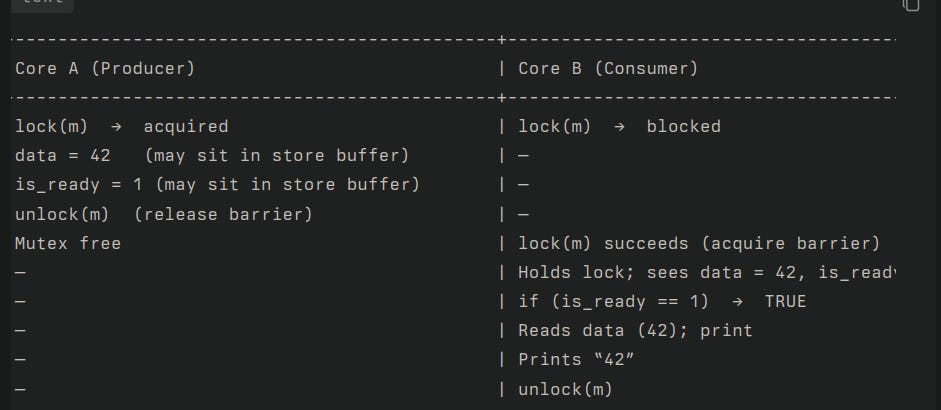
Execution Flow: WITH Locks
Now, let's introduce a new set of rules that apply when we use a mutex.
The Axioms of a Mutex
Axiom 5: Mutual Exclusion
Only one thread can hold a given mutex at any one time. A thread calling lock() will block (wait) until the mutex is released by its current owner.
Axiom 6: The Memory Barrier Handshake
A mutex_unlock operation creates a release barrier. This acts as a command: "Commit all my buffered writes now. Ensure all my previous memory operations are visible to the rest of the system before the lock is actually released."
A mutex_lock operation creates an acquire barrier. This acts as a command: "Before I proceed, I must synchronize my local view of memory with the latest changes from whoever last released this lock. Invalidate my stale cache entries."
These two barriers work together. The release publishes changes; the acquire receives them. This creates a "happens-before" relationship. The unlock on Thread A happens-before the subsequent lock on Thread B.
Producer Code (Thread P on Core A):
lock(m);
data = 42;
is_ready = 1;
unlock(m);
Consumer Code (Thread C on Core B):
lock(m);
if (is_ready == 1)
print(data);
unlock(m);
Let's trace the execution flow with these new, powerful rules.
Deadlock
A deadlock is a state in which two or more threads are blocked forever, each waiting for a resource held by the other. The most common cause of deadlock with mutexes is acquiring multiple locks in an inconsistent order.
The Deadly Embrace
Imagine two threads, Thread A and Thread B, and two mutexes, M1 and M2.
Thread A locks M1.
Thread B locks M2.
Thread A tries to lock M2, but it's held by Thread B. Thread A blocks.
Thread B tries to lock M1, but it's held by Thread A. Thread B blocks.
pthread_mutex_t M1, M2;
// Transferring a resource from an object protected by M1
// to an object protected by M2.
void transfer_resource() {
// Enforce a global lock order: Lock the mutex with the lower memory address first.
if (&M1 < &M2) {
pthread_mutex_lock(&M1);
pthread_mutex_lock(&M2);
} else {
pthread_mutex_lock(&M2);
pthread_mutex_lock(&M1);
}
}"Any thread that needs to lock both M1 and M2 must always lock M1 first, then lock M2."
Semaphores
A semaphore is a synchronization primitive that is a generalization of a mutex. It was invented by the legendary Dutch computer scientist Edsger W. Dijkstra in the mid-1960s.
A semaphore is essentially a non-negative integer counter that is manipulated by two atomic operations:
P() (from the Dutch proberen, "to test" or "to probe"). Also known as wait() or down().
V() (from verhogen, "to increment"). Also known as post(), signal(), or up().
The semaphore's internal integer counter tracks the number of available "permits" or "resources".
The logic of the two operations is as follows:
wait(semaphore):
Atomically decrement the semaphore's internal counter.
If the counter's value becomes negative, the calling thread is blocked and placed into a waiting queue.
If the counter's value is zero or positive, the thread continues execution.
post(semaphore):
Atomically increment the semaphore's internal counter.
If there are any threads blocked waiting on this semaphore (i.e., the counter was negative before the increment), wake one of them up.
Key Difference from a Mutex:
A mutex has the concept of "ownership". The thread that locks it must be the one to unlock it. A semaphore is a signaling mechanism; it has no concept of ownership. Any thread can post to a semaphore, even if it never called wait. This makes it a powerful tool for more complex synchronization scenarios beyond simple mutual exclusion.
There are two main types of semaphores:
Binary Semaphore: The counter is initialized to 1. It can only be 1 (resource available) or 0 (resource unavailable). It behaves almost identically to a mutex. If you wait when it's 1, it becomes 0 and you proceed. If you wait when it's 0, you block. post changes it from 0 to 1 and wakes a waiting thread.
Counting Semaphore: The counter can be initialized to any non-negative integer N. This allows up to N threads to pass the wait operation without blocking. It is used to guard a pool of N identical resources.
example use case :- suppose there is a function which can only run on a GPU but your GPU only has 4 cores, so you want this function to be at a time picked up by only 4 threads, this is where semaphores can be useful
Spinlocks
A spinlock is a type of lock that avoids blocking in the traditional sense. Instead of yielding the CPU when the lock is unavailable, the thread enters a tight loop, repeatedly checking the lock's status until it becomes free. This action of looping is called "spinning." The thread remains active and scheduled, consuming 100% of its CPU core while it waits.
When and Why to Use Spinlocks
The decision to use a spinlock versus a mutex is a pure performance trade-off, hinging on the expected wait time for the lock.
Cost of a Mutex: The overhead of a context switch. This is a relatively high, fixed cost. It involves saving the thread's state, updating scheduler data structures, and then later restoring the thread's state. This can take thousands of CPU cycles.
Cost of a Spinlock: The CPU cycles wasted while spinning. This cost is variable and directly proportional to how long the lock is held by another thread.
Use a spinlock when the critical section is very short
Spinlocks are only effective on multi-core systems. On a single-core system, they are a disaster. If a thread starts spinning on a single-core machine, it is consuming the only available CPU
Condition Variables
A condition variable is a synchronization primitive that allows threads to block (wait) until a particular condition, related to shared data, becomes true
lets look at what problem they solve through an example
// BROKEN AND INEFFICIENT "SOLUTION"
pthread_mutex_lock(&queue_mutex);
while (is_queue_empty(&my_queue)) {
// What do we do here? If we just loop, we are holding the lock
// and spinning, preventing the producer from ever getting the lock
// to add an item. This is a deadlock.
}
// consume item
pthread_mutex_unlock(&queue_mutex);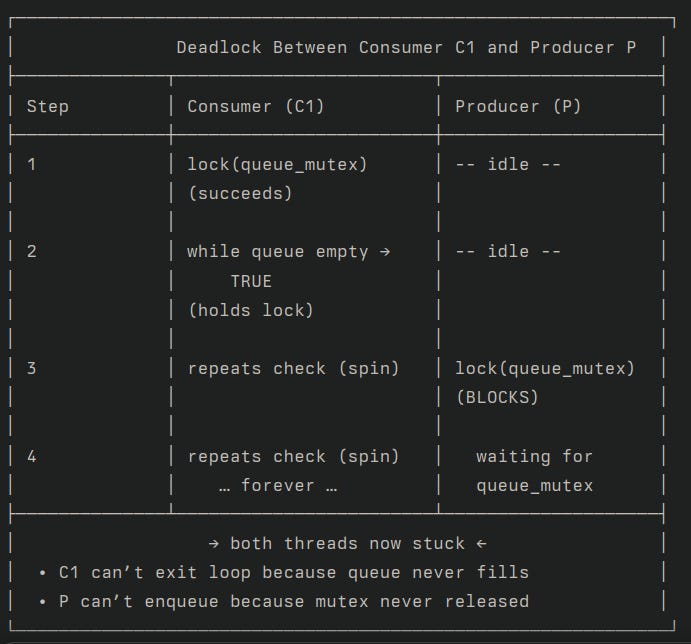
how condition variables solve this
A thread acquires a mutex to protect the shared data.
It checks if a condition is true.
If the condition is false, the thread atomically unlocks the mutex and goes to sleep on the condition variable. This is the magic step.
Another thread (the producer/modifier) acquires the mutex, changes the state of the shared data, and potentially makes the condition true.
The producer thread then signals the condition variable, which wakes up one or more of the waiting threads.
A woken-up thread then re-acquires the mutex and checks the condition again before proceeding.
Read-Write Locks
A shared data structure that is read often but written rarely doesn’t need every access to be exclusive.
A standard mutex forces both reads and writes to wait for one another, so even purely read-only threads are serialized, creating needless slowdown.
A read-write lock (rwlock) fixes this by offering
– read (shared) lock: many threads can read simultaneously because they don’t change the data.
– write (exclusive) lock: a writer gains sole access, ensuring updates stay consistent.
The rules of a read-write lock are:
Multiple Readers Allowed: Any number of threads can hold a read lock on the resource simultaneously.
Exclusive Writer: Only one thread can hold a write lock.
Writers Exclude Everyone: If a thread holds a write lock, no other thread (neither reader nor writer) can acquire any lock.
Readers Exclude Writers: If any thread holds a read lock, any thread attempting to acquire a write lock must wait until all readers have released their locks.
what if a stream of new readers keeps arriving while a writer is waiting?
This leads to two common implementation strategies, which address the "reader-writer problem."
Reader-Preference:
Policy: If the lock is held by readers, an incoming reader is granted access immediately. A waiting writer will only get the lock when all readers (including the newly arrived ones) have finished.
Writer-Preference:
Policy: If a writer is waiting for the lock, any newly arriving readers will be blocked. They will be queued up behind the waiting writer. The writer gets the lock as soon as the current readers finish.
Barriers
A barrier is a synchronization primitive that forces a group of participating threads to all wait at a specific point (the "barrier point") until every thread in the group has reached that point. Once the last thread arrives, all threads are released simultaneously and can proceed with their next phase of computation.
Barriers are ideal for algorithms that are broken down into distinct phases or stages, where the results of one phase are needed by all threads before the next phase can begin
Atomics
Starting with the C11 standard, the C language gained native support for atomic operations. This is a massive improvement over relying on platform-specific inline assembly or compiler intrinsics. The features are primarily defined in the <stdatomic.h> header.
An atomic operation is one that is guaranteed by the hardware to execute indivisibly. When a thread performs an atomic operation on a variable, no other thread can see the variable in a half-modified state. The entire operation (read, modify, and write) completes as a single, uninterruptible step.
C11 _Atomic Types and Operations
You can make any integer type, pointer, or struct/union (of a certain size) atomic by using the _Atomic keyword (or the more convenient atomic_int, atomic_bool, etc. type aliases from <stdatomic.h>).
Once a variable is declared as atomic, you cannot use standard operators like ++, +=, or = on it. You must use the special atomic functions
that’s it for this blog guys, next will be diving deeper into Golang concurrency, until then bbye.
This was a great read, I have mostly looked at them from cpp side it's almost similar.