
the hitchhiker’s guide to golang concurrency

Go has special Threads called Go-Routines.
they are different from your OS-Threads in the way that they are very light weight, each with a stack size of 2kb that can grow and shrink compared of 1-8 mb of a local os-thread
syntax
package main
import (
"fmt"
"time"
)
func sayHello() {
fmt.Println("Hello from the sayHello goroutine!")
}
func main() {
go sayHello()
fmt.Println("Hello from the main goroutine.")
time.Sleep(100 * time.Millisecond)
}what happens if you remove time.sleep at the last? the sayHello function will not print.
think of it like this, the main function is run by a main go-routine and it is not in the habit of waiting for smaller go-routines.
Using time.Sleep is a fragile hack. We need a deterministic synchronization mechanism. This is the perfect segue into sync.WaitGroup, which we will cover next.
It's essentially a concurrent counter that allows a goroutine (usually the main goroutine) to block until a collection of other goroutines have finished their tasks.
A WaitGroup has three core methods:
Add(delta int): This increments the WaitGroup's internal counter by delta.
You call this before you launch the goroutine(s). If you have N goroutines to wait for, you would call wg.Add(N).
Done(): This decrements the WaitGroup's counter by one.
This is called by the worker goroutine itself, typically as the last action before it returns, often using defer. It's a signal from the goroutine saying, "I have finished my work."
Wait(): This blocks the goroutine that calls it until the WaitGroup's internal counter becomes zero.
This is called by the goroutine that needs to wait (e.g., the main goroutine).
let’s see this in code
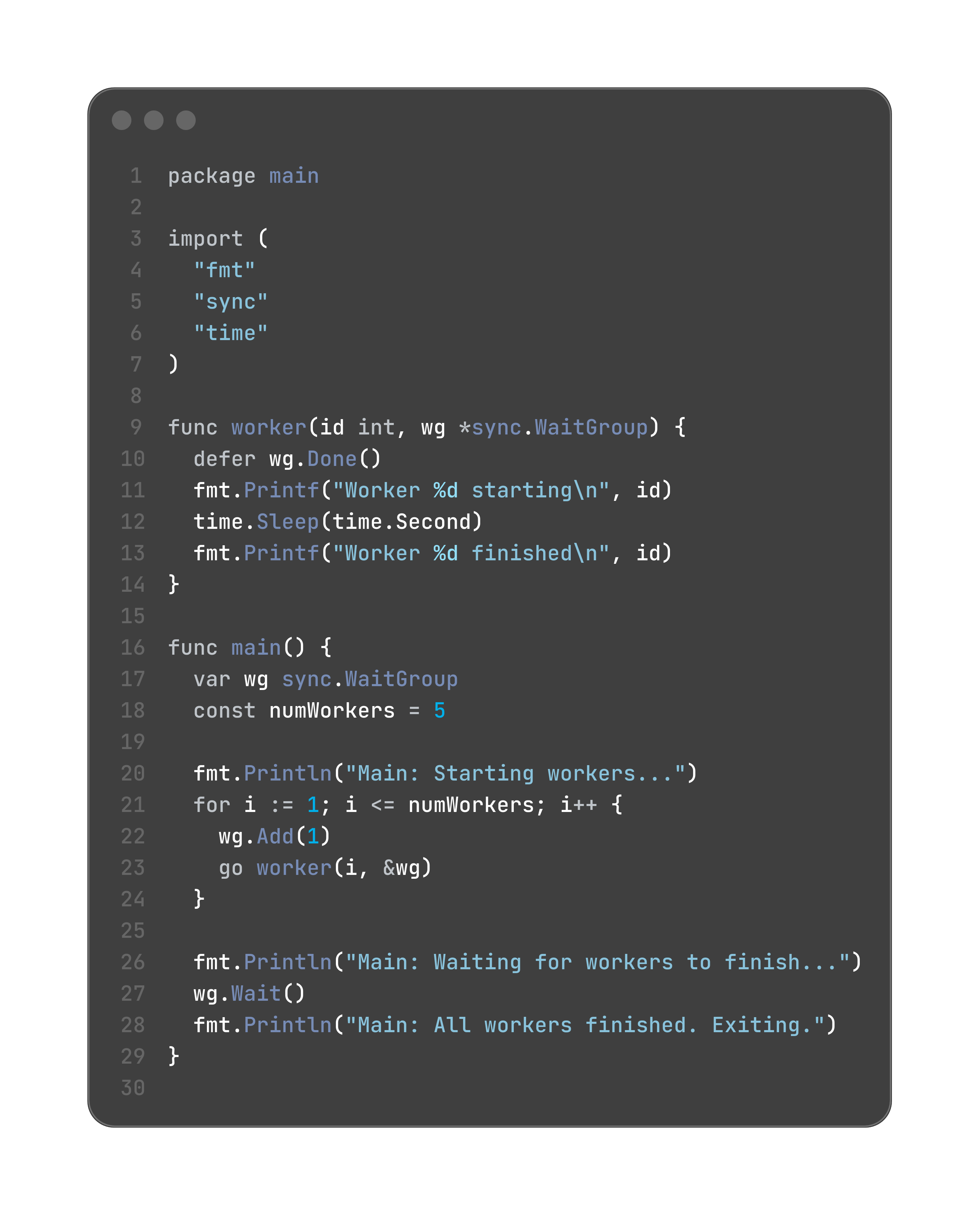
Execution Flow and Output:
Main: Starting workers...
Main: Waiting for workers to finish...
Worker 3 starting
Worker 5 starting
Worker 1 starting
Worker 4 starting
Worker 2 starting
Worker 3 finished
Worker 5 finished
Worker 1 finished
Worker 4 finished
Worker 2 finished
Main: All workers finished. Exiting.
now you might be wondering why the output is not sequential, that is because there is a difference between starting a go routine and scheduling a go routine.
the scheduling part was sequential. and places this new goroutine into a runnable queue. but when the go routines are run they are not sequential, the queue does not take care of the order
Channels
channels are a way for go-threads to communicate information with each other, obviously they could have communicated by read global variables but that is discouraged in golang’s philosophy and channel communication is encouraged.
You declare a channel using the chan keyword followed by the type of data it will carry.
var myIntChannel chan int // A channel that carries integers
var myStringChannel chan string // A channel that carries strings
var myStructChannel chan MyStruct // A channel that carries values of type MyStructLike maps and slices, a channel is a reference type. Its zero value is nil. Before you can use a channel, you must initialize it with the built-in make() function.
myIntChannel = make(chan int) Unbuffered Channels and Rendezvous
An unbuffered channel is created with a capacity of zero. This is the default.
ch := make(chan int) // or make(chan int, 0)An unbuffered channel has a unique and powerful synchronization property: it forces a rendezvous.
A send operation on an unbuffered channel will block until another goroutine is ready to receive from that same channel.
Likewise, a receive operation will block until another goroutine performs a send.
let’s look this through a concrete code example
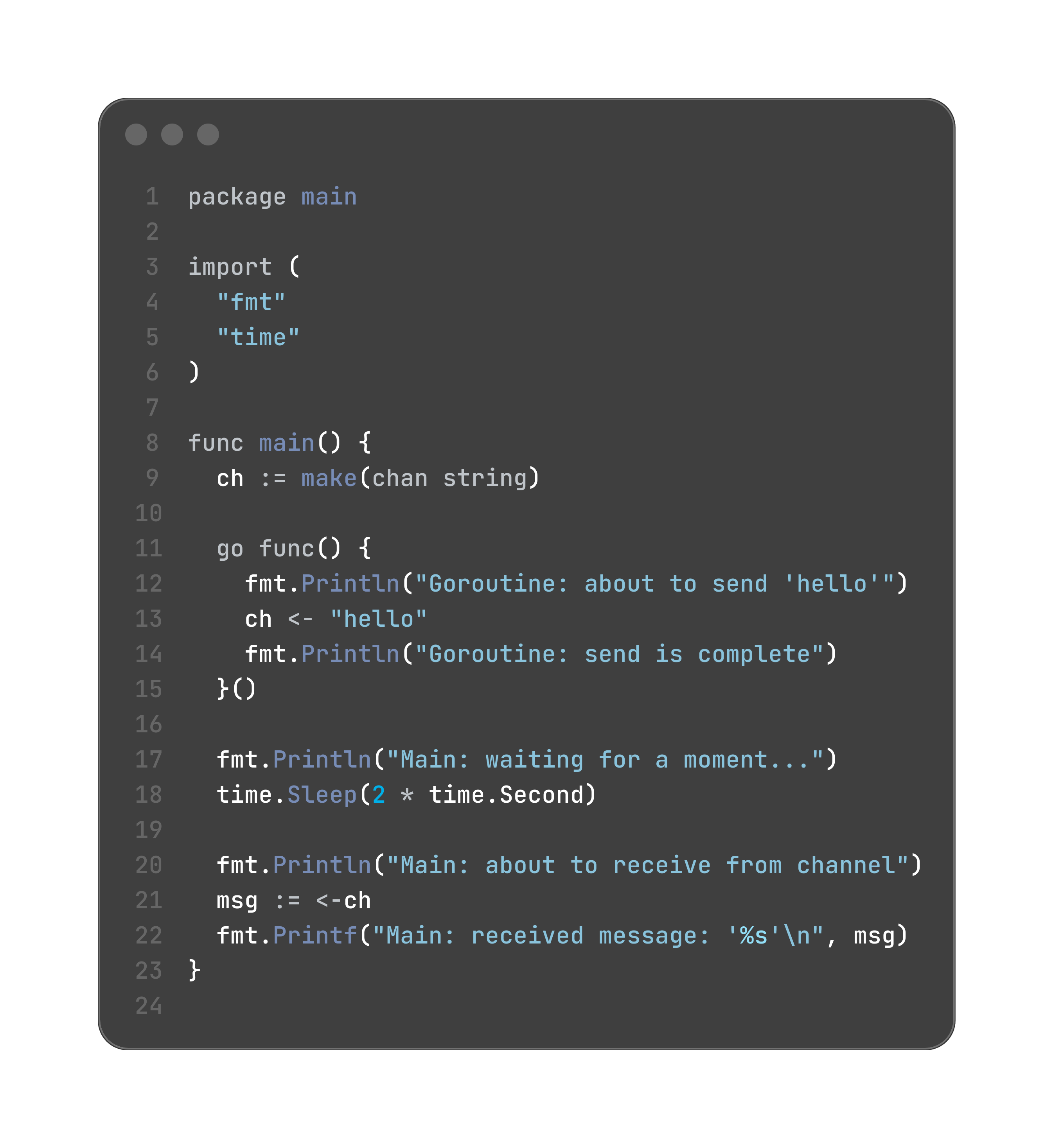
The Transactional View
The Go runtime acts as a mediator for the unbuffered channel.
Sender Arrives First:
Goroutine A executes ch <- "hello".
The runtime sees there is no receiver waiting.
The runtime suspends Goroutine A. It is now blocked, waiting for a partner.
Receiver Arrives:
Goroutine B executes msg := <-ch.
The runtime sees there is a sender (Goroutine A) waiting.
The Rendezvous Transaction Begins:
The runtime takes the value ("hello") directly from the sending goroutine (A).
It passes this value to the receiving goroutine (B).
The value is assigned to the variable msg.
Now that the transaction is complete, the runtime marks both Goroutine A and Goroutine B as runnable again.
The Transaction Ends.
Execution Continues:
At this point, the statement msg := <-ch is complete in Goroutine B. The line of code is finished. Goroutine B can now move on to the next statement, which is fmt.Printf.
Simultaneously, the statement ch <- "hello" is complete in Goroutine A. Goroutine A can now move on to its next statement.
it’s also possible that instead of the send, our execution first gets to the receive point and blocks the main goroutine until the send is done by another goroutine
Buffered Channels and Decoupling
A buffered channel is created with a capacity greater than zero.
ch := make(chan int, 3) // A channel that can hold up to 3 integersA buffered channel decouples the sender and receiver.
A send operation on a buffered channel will only block if the channel's buffer is full. If there is space, the send completes immediately, and the value is stored in the channel's buffer.
A receive operation will only block if the channel's buffer is empty.
This allows the sender and receiver to work at different paces, as long as the buffer doesn't fill up or empty out.
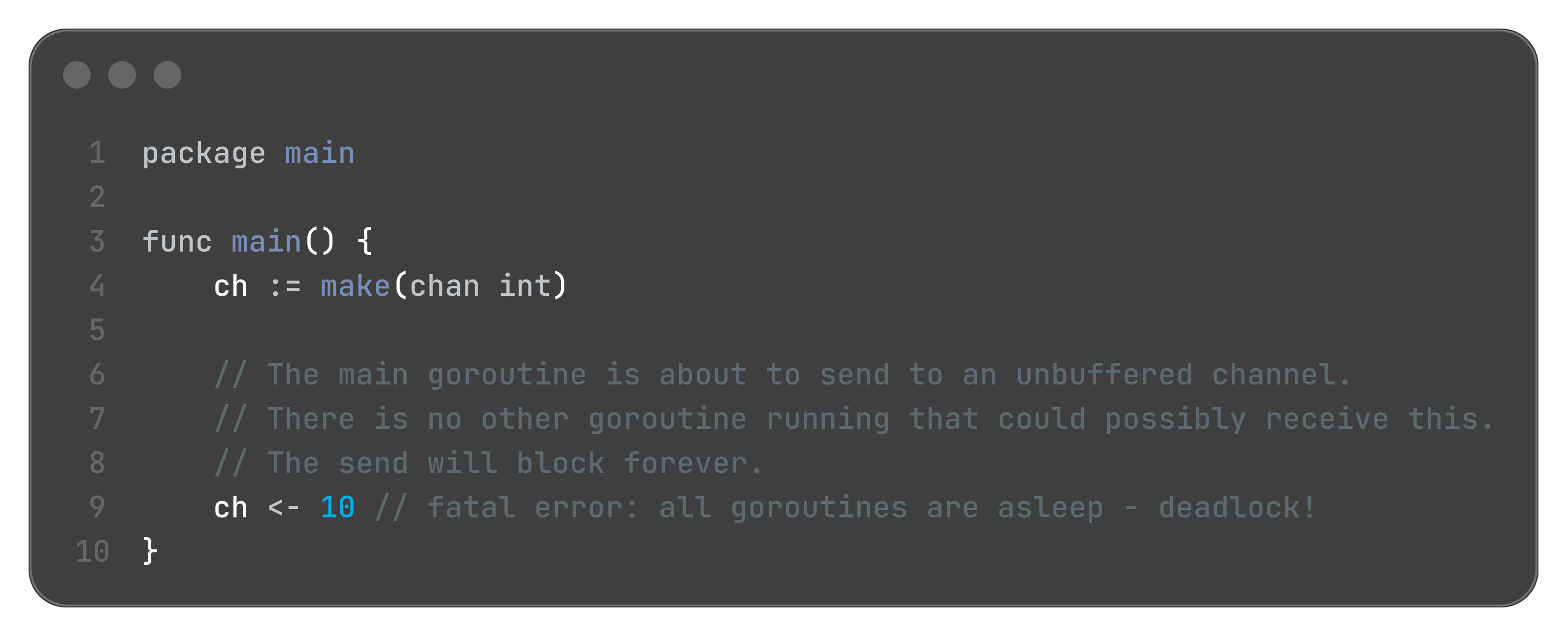
Deadlocks with Channels
A deadlock occurs when all goroutines in a program are blocked, waiting for something that can never happen.
close(channel)
Signals that no more values will ever be sent on this channel.
It is a final "goodbye" from the sender(s).
Properties of a Closed Channel:
Sending to a closed channel will cause a panic. This is a strict rule: once you say you're done sending, you must be done.
Receiving from a closed channel never blocks. It immediately returns a value.
If there are values still in the buffer, it returns them one by one.
Once the buffer is empty, any subsequent receives will immediately return the zero value for the channel's type (e.g., 0 for int, "" for string, nil for pointers).
How does a receiver know the difference between a legitimate zero value and a zero value from a closed, empty channel? The receive operator has a special two-variable form:
value, ok := <-channelok is a boolean.
If ok is true, the value was a legitimate value sent on the channel.
If ok is false, it means the channel is closed and empty. The value will be the zero value for its type
This brings us to the most elegant way to receive all values from a channel until it is closed: a for...range loop.
for item := range channel {
// This loop will automatically receive values from the channel
// and assign them to 'item'.
// The loop will automatically break when the channel is closed
// and all values have been drained from its buffer.
}let’s see this all in action through a code sampel
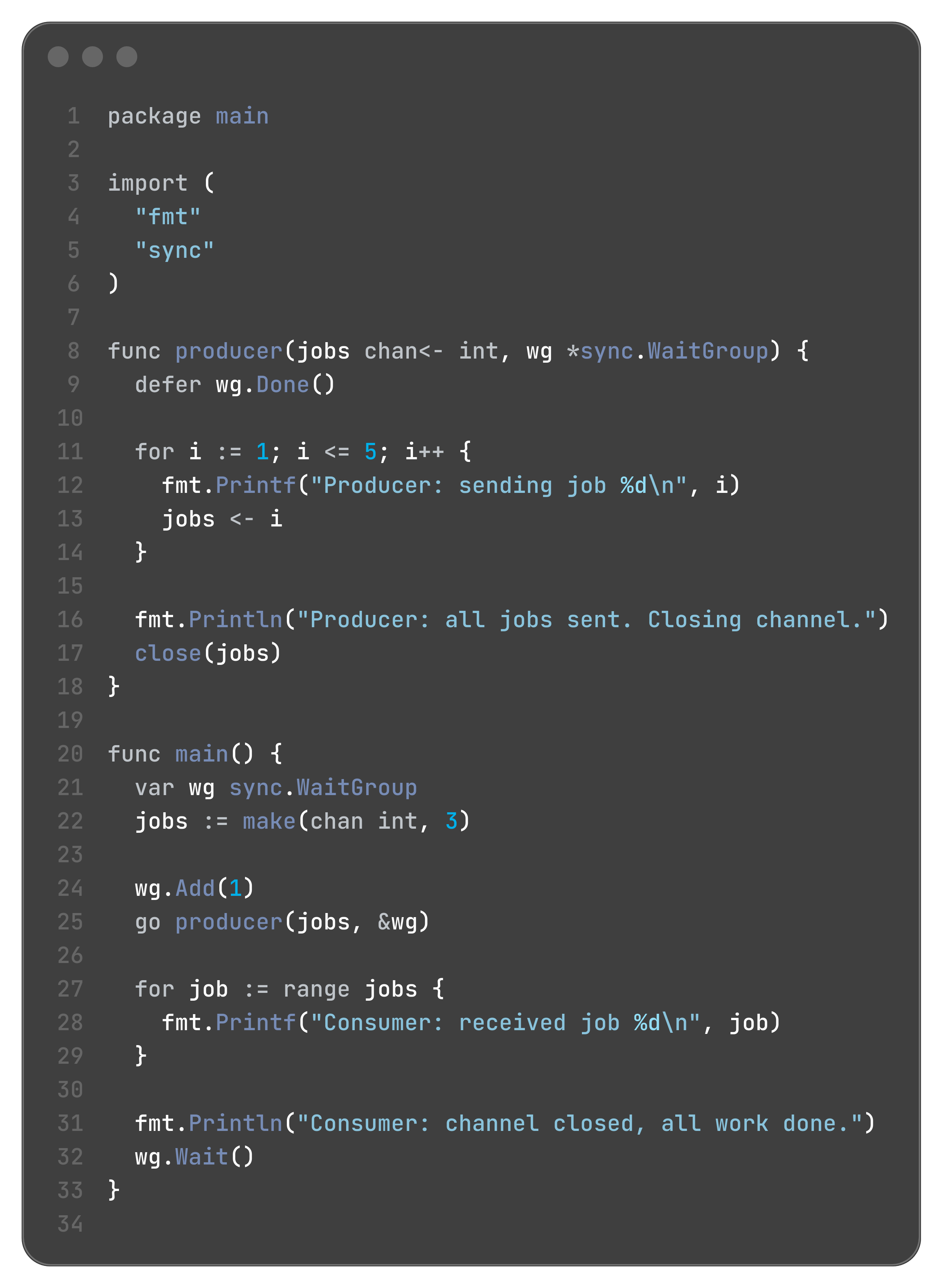
if you see carefully, there is a race condition between producer function and for…range loop.
what if the loop win? then the jobs channel would be empty and remember what we said above? empty channels are blocking. so this for loop will get blocked until producer sends some value in this.
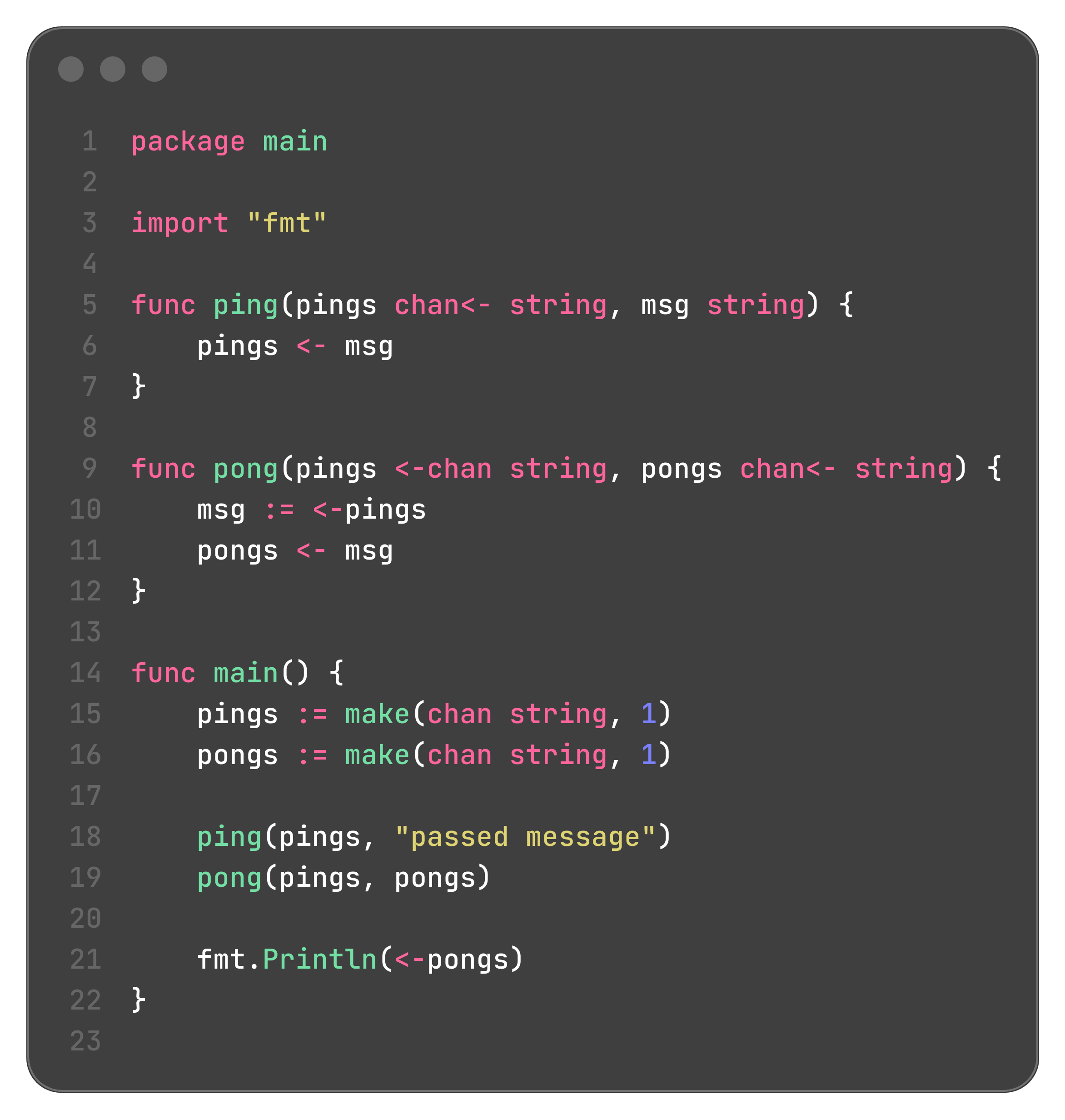
Directional Channels (chan<- and <-chan) for API Safety
<-chan T: A receive-only channel of type T. You can only receive from it (val := <-ch). You cannot send to it or close it.
chan<- T: A send-only channel of type T. You can only send to it (ch <- val). You cannot receive from it or close it.
This is extremely useful for writing clear APIs.
A function that produces data should accept a send-only channel as an argument.
A function that consumes data should accept a receive-only channel as an argument.
Common Channel Use Cases
This section is about patterns—recipes for structuring concurrent code. We'll look at three of the most fundamental: Worker Pools, Fan-in/Fan-out, and Pipelines
Worker Pools
The idea is to control the level of concurrency for a set of tasks. Instead of launching a new goroutine for every single task (which could be thousands or millions), you launch a fixed number of persistent "worker" goroutines. You then feed tasks to these workers via a channel.
Real-World Example: Concurrent Thumbnail Generator
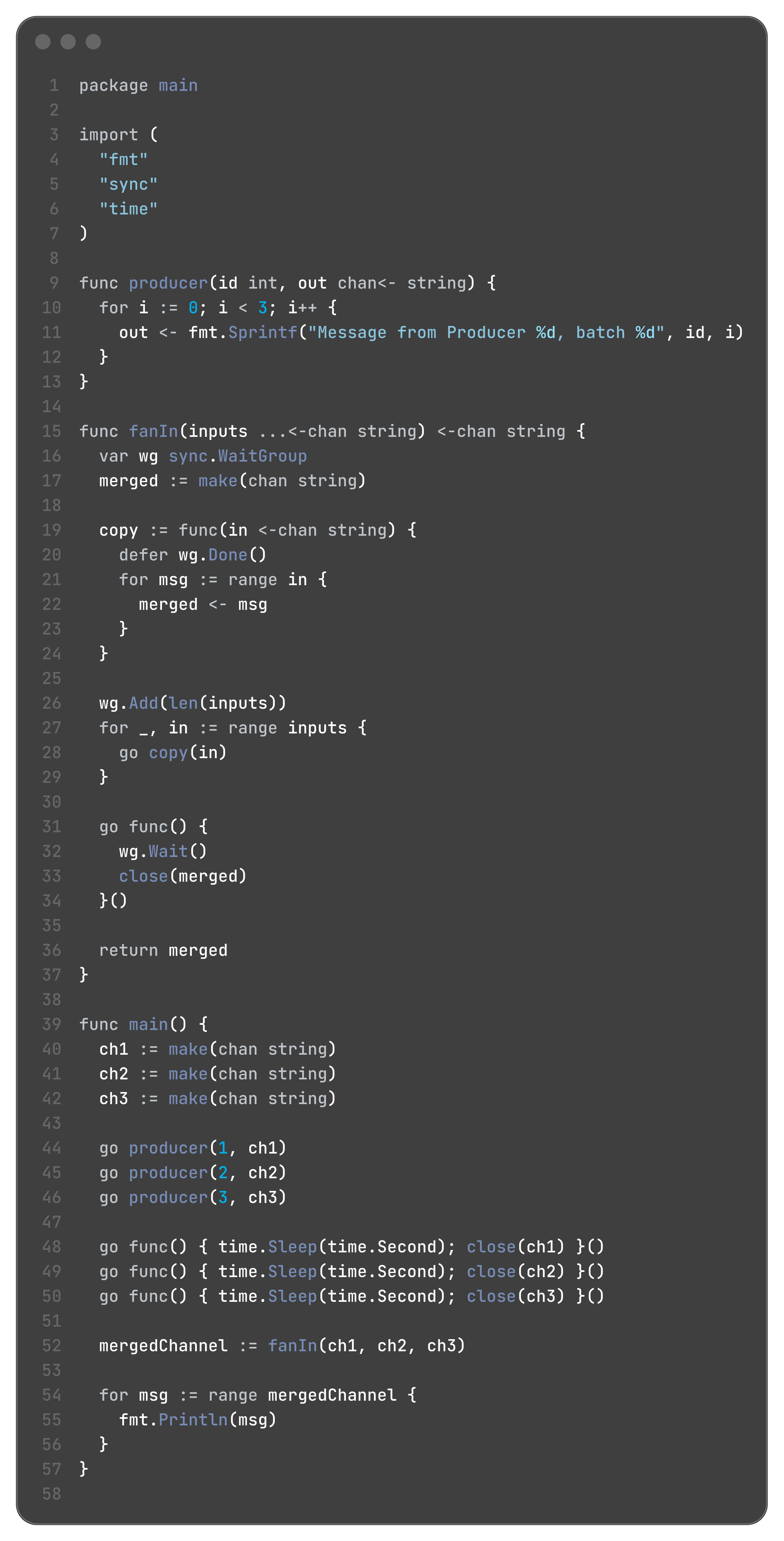
Fan-in / Fan-out
this one honestly I also do not understand much, so I am just pasting the code snippet here
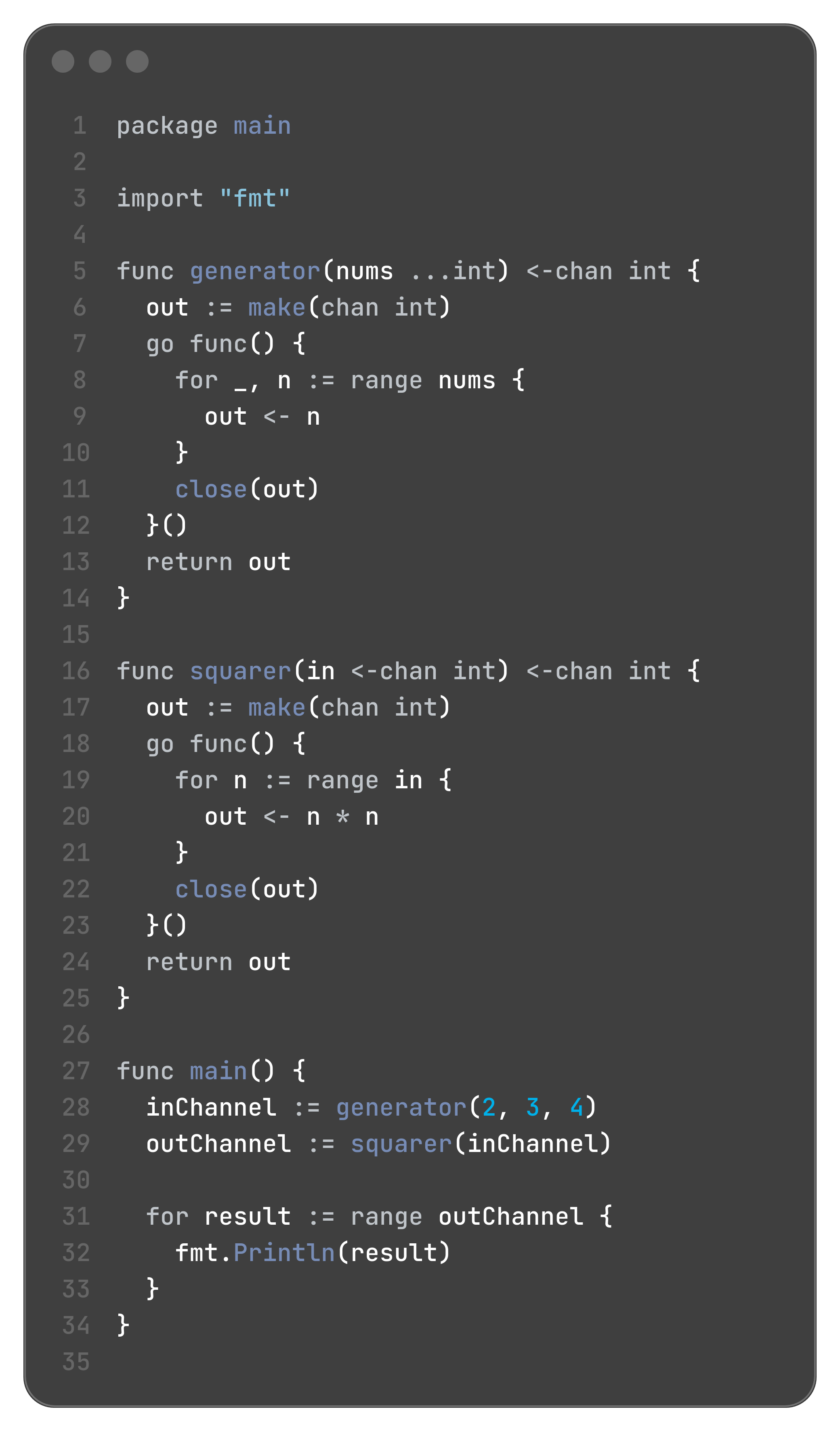
Pipelines
A pipeline is a chain of processing stages connected by channels. Each stage is a goroutine that:
Receives values from an upstream channel.
Performs some function on that value.
Sends the result to a downstream channel.
This creates a concurrent assembly line. It's a very powerful and elegant way to structure data processing tasks.
The select Statement
A select statement blocks until one of its cases can run, then it executes that case. If multiple cases are ready at the same time, it chooses one at random to execute. This randomness is important because it ensures fairness and prevents a "busy" channel from always starving out another channel.
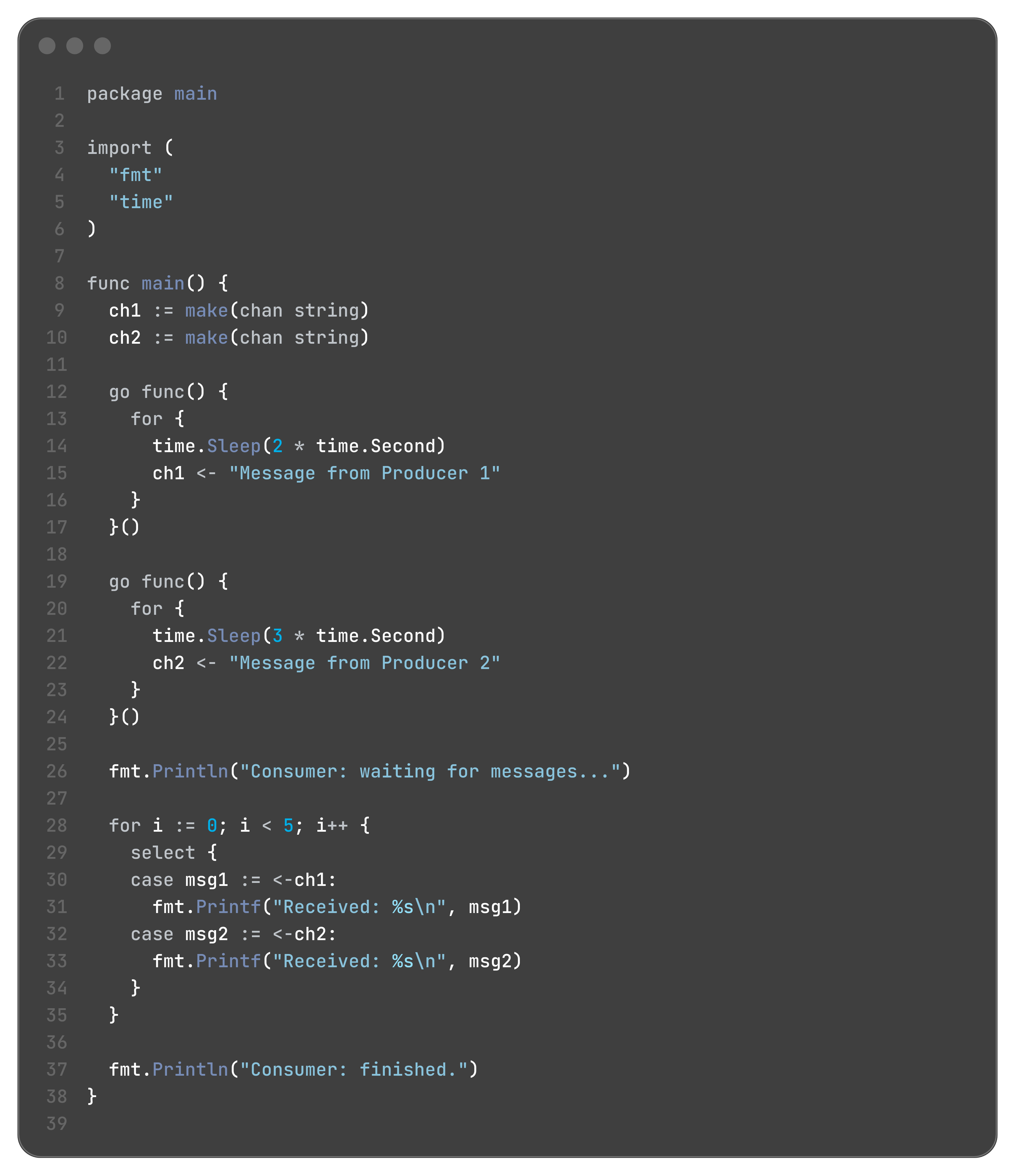
Waiting on Multiple Channels
This is the primary use case for select. Imagine a goroutine that needs to process work coming from two different producers.
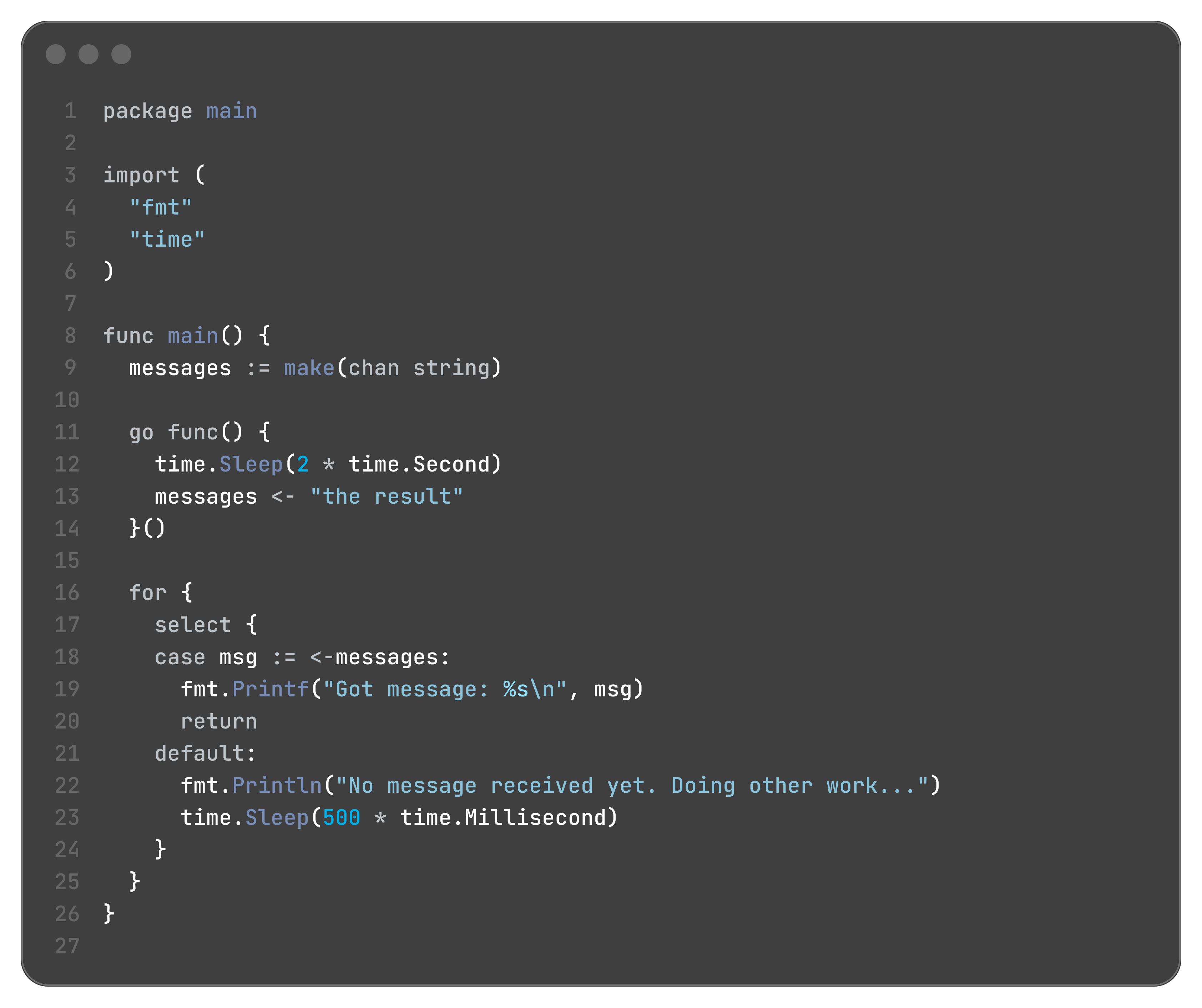
A select statement normally blocks. However, you can make it non-blocking by adding a default case.
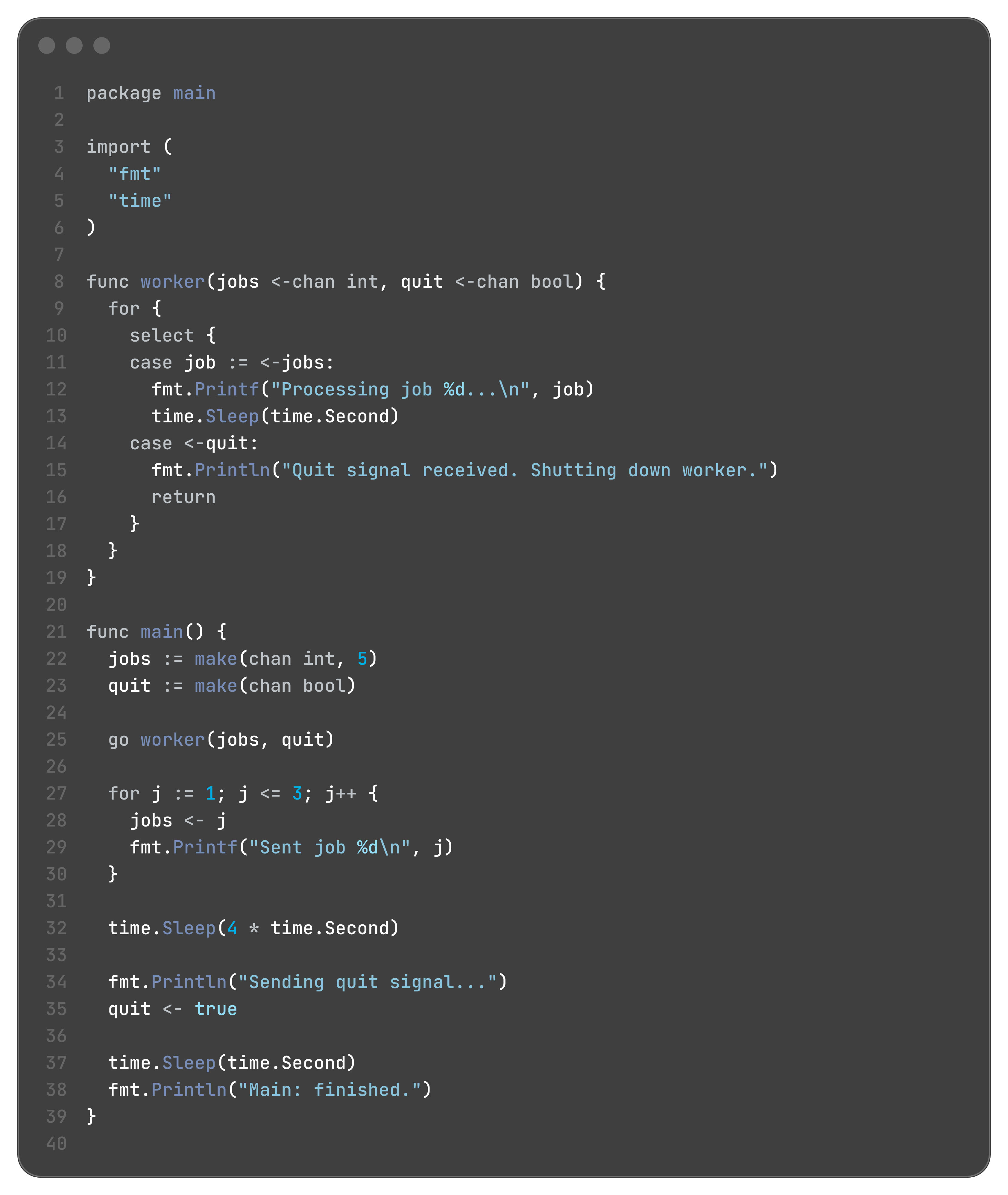
The most powerful and common pattern is combining for and select. This creates a goroutine that acts like a server, continuously processing events from multiple channels until it receives a signal to stop.
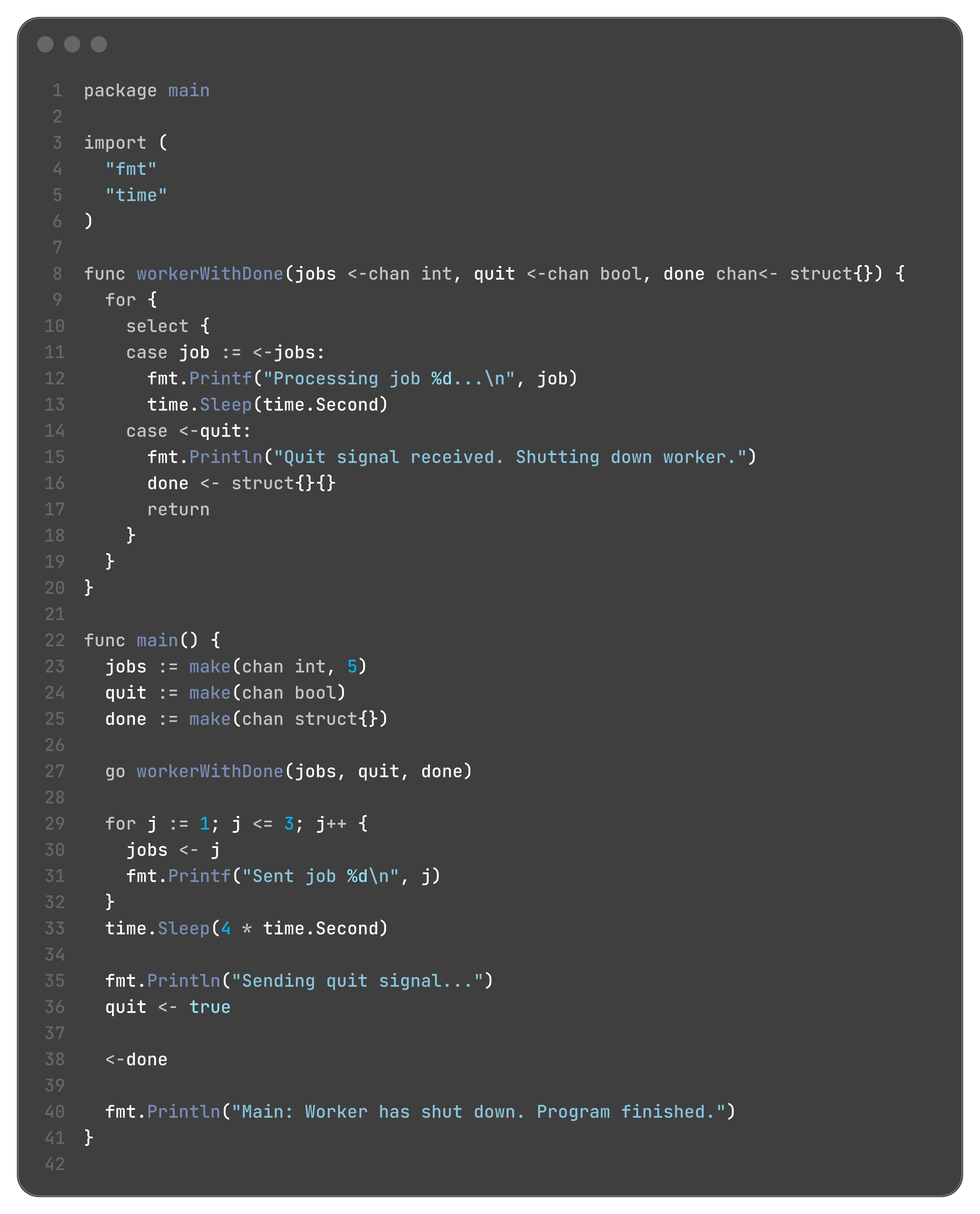
note : instead of the last sleep we could also have used wait groups or there is a nice cool trick which simulates wait groups using channels itself
Timeouts and Tickers
Often, a goroutine can't afford to wait forever on a channel operation. You might be making a network request or waiting for a job from a queue, and you need to give up after a certain amount of time.
The time.After function is the perfect tool for this.
When you combine this channel with a select statement, you can create a timeout.
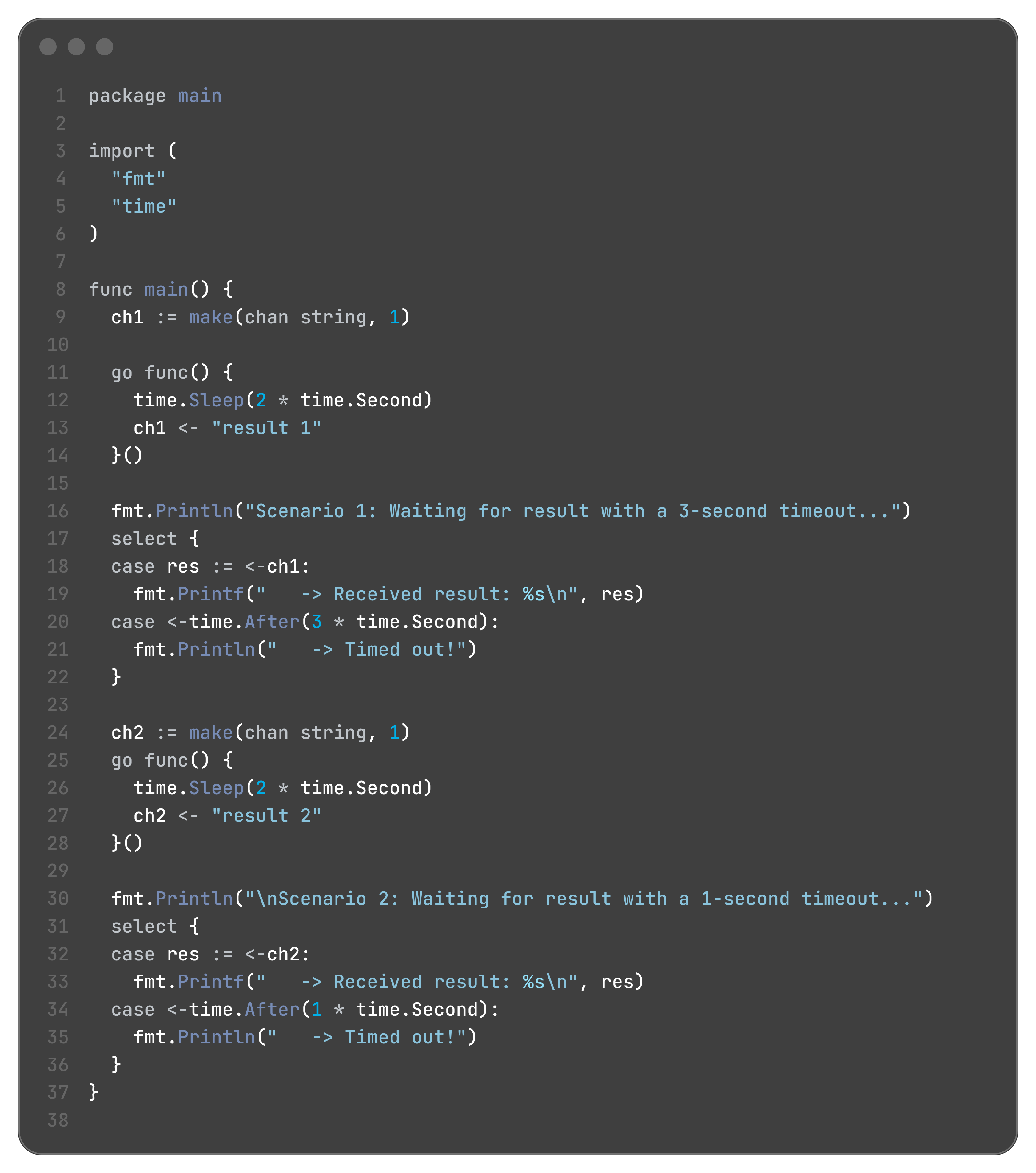
Output:
Scenario 1: Waiting for result with a 3-second timeout...
-> Received result: result 1
Scenario 2: Waiting for result with a 1-second timeout...
-> Timed out!time.Ticker for Periodic Tasks
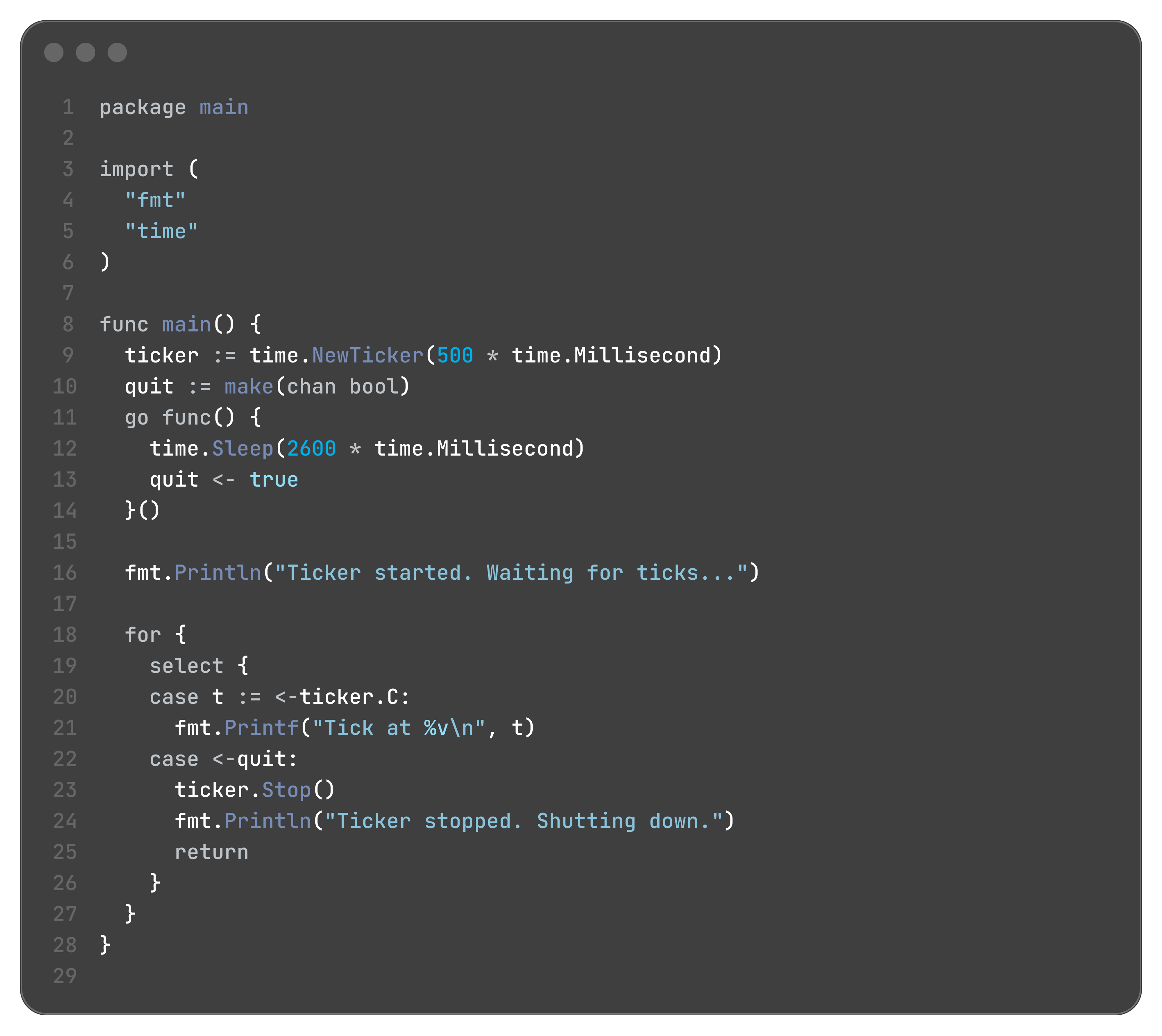
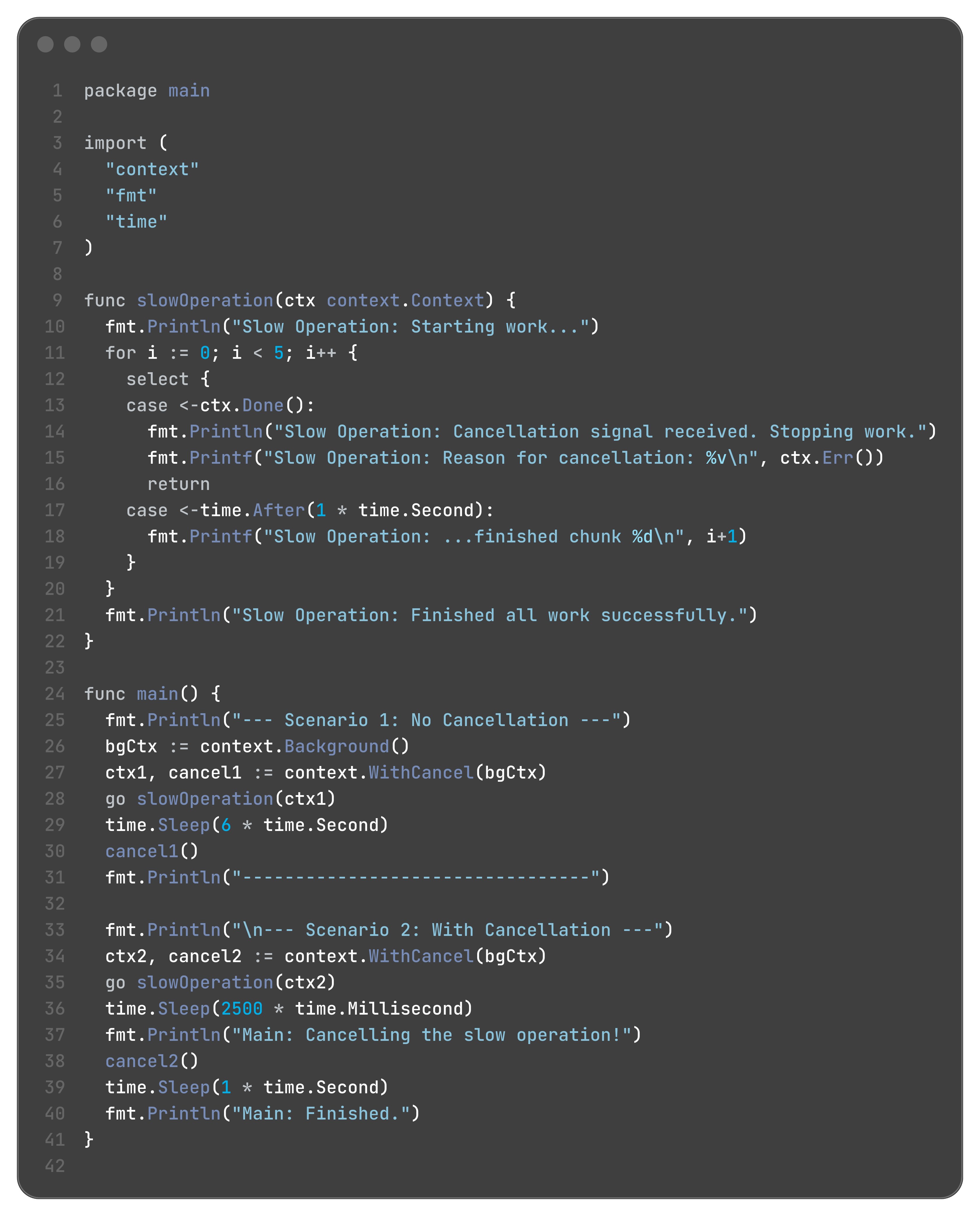
Graceful Shutdown and Cancellation with context
The Problem It Solves:
Imagine you have a web server. A user sends an HTTP request.
Your server handler starts a goroutine to handle the request.
This goroutine makes a call to a database.
It also makes a call to a microservice.
The microservice itself might make other calls.
Now, what happens if the user closes their browser? The initial HTTP request is cancelled. All the downstream work being done by the database and microservice calls is now pointless. We need a way to tell all the goroutines involved in this request, “Stop your work, the result is no longer needed.”
The context package provides this cancellation signal.
Error Handling in Concurrent Code
In a standard sequential program, error handling is straightforward: a function returns an error, and the caller immediately checks if err != nil.
In a concurrent program, this breaks down. When you launch a goroutine with go myFunction(), you can’t get a return value. So how does the goroutine report back if it fails? What if you launch 100 goroutines and need to know if any of them failed?
Simply logging the error from within the goroutine is not enough. The main goroutine, which launched the work, often needs to know about the failure to decide on a course of action (e.g., cancel other workers, retry the operation, or exit).
We need a pattern to propagate errors out of goroutines and aggregate them for the calling function.
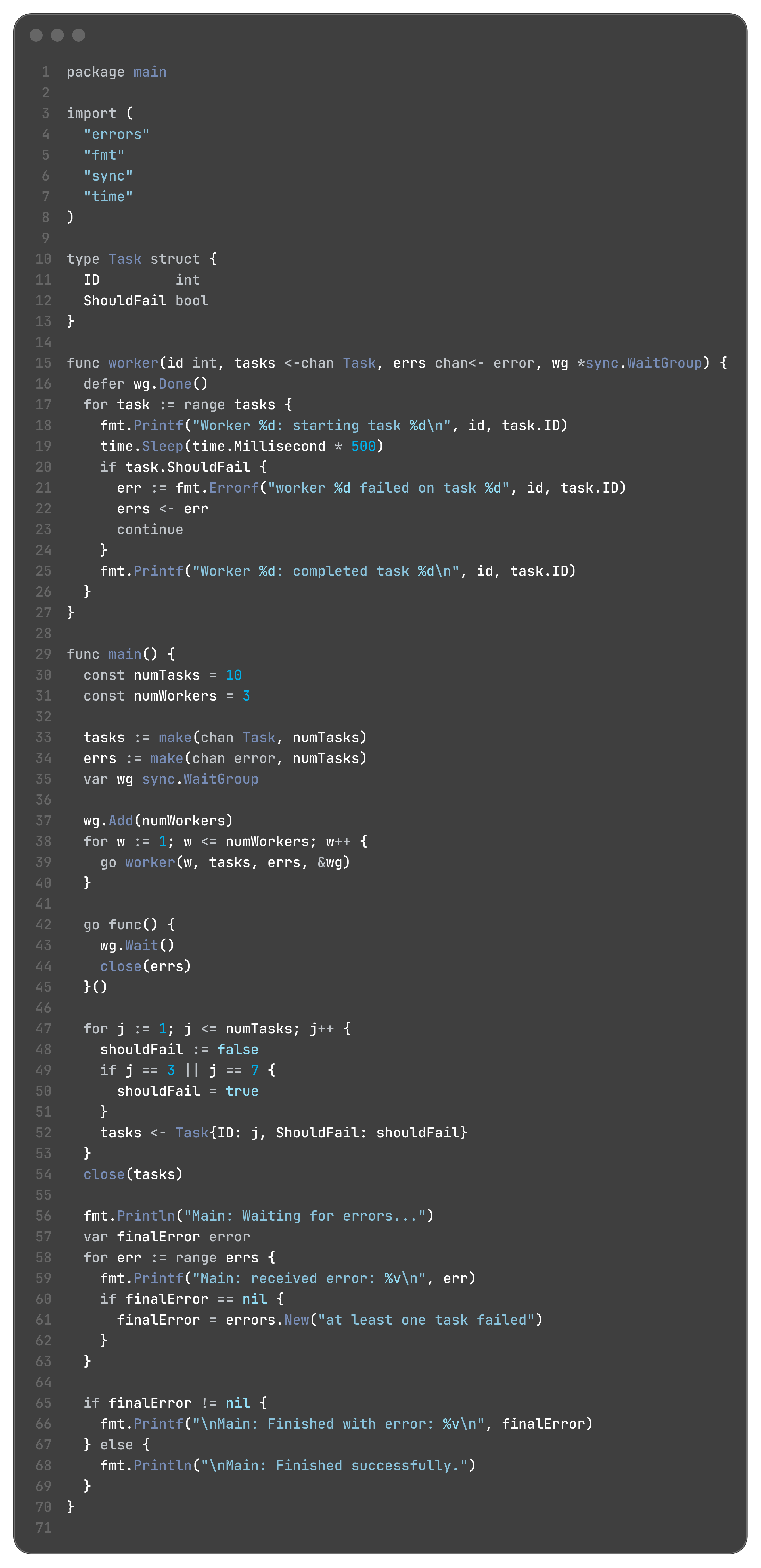
5.2.1: Using a Dedicated Error Channel
The most idiomatic Go way to solve this is to use the same tool we use for data: a channel. We can create a dedicated channel just for passing error values.
The Pattern:
Create a buffered channel for errors. The buffer size is typically the number of workers, so that no worker will block when trying to send an error.
Pass this error channel to each worker goroutine.
Inside the worker, if an error occurs, send it into the error channel instead of just logging it. If no error occurs, the worker does not send anything.
The main goroutine, after launching the workers, must have a way to collect and process these errors.
5.2.2: Combining WaitGroup and Error Aggregation
The main goroutine cannot simply range over the error channel, because it doesn’t know how many errors to expect. If it tries to read N errors (for N workers), it will deadlock if only one worker fails.
The correct pattern is to use a sync.WaitGroup to know when all workers have finished their attempts. Then, and only then, can we safely close the error channel and read whatever errors were sent.
The Full Pattern:
Create a tasks channel and an errs channel.
Create a sync.WaitGroup.
Start a fixed number of workers. In each worker:
defer wg.Done().
Process tasks.
If a task fails, send the error to the errs channel.
Start a separate “closer” goroutine. This goroutine’s only job is to wg.Wait() and then close(errs). This is the key to breaking the deadlock.
The main goroutine is now free to range over the errs channel. This loop will block until the closer goroutine closes the channel, at which point it will process any received errors and then terminate.
this is it for this blog, to be honest I am also not an expert on go-concurrency as of now but will try to learn as much as we can.