
BROADCASTING
notes for myself

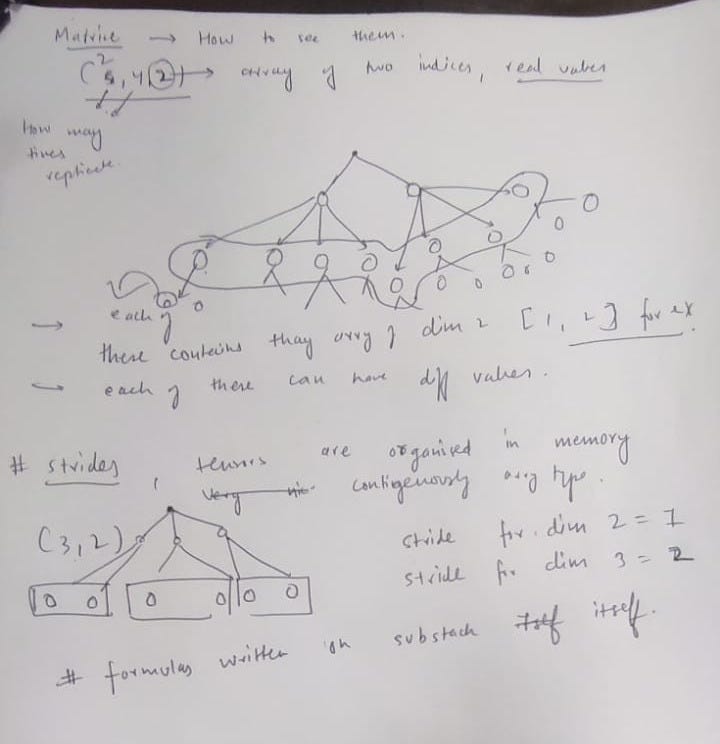
Given a tensor with Shape (d0,d1,…,dn−1), the stride sk for dimension k is the product of the sizes of all subsequent dimensions.
for the last dimension (k = n-1):
s(n-1) = 1
for any other dimension k (counting backwards from n-2 down to 0):
s(k) = s(k+1) * d(k+1)
the explicit formula:
s(k) = product from j = k+1 to n-1 of d(j)
The Memory Offset Formula (Linear Index)
given a specific logical index (i0, i1, ..., in-1) and strides (s0, s1, ..., sn-1):
contiguous vs non-contiguous memory:
a tensor is contiguous if its elements are stored in memory in the order they’re traversed when incrementing indices from right to left (axis -1 moves fastest).
example:
matrix a, shape (2, 3), storage: , strides: (3, 1).
after transpose b = a.t(), shape (3, 2), storage unchanged, strides: (1, 3).
iterating along axis 1 of b now jumps by 3 in memory—not sequential. this is non-contiguous.
why it matters:
operations like .view() need contiguous memory. if a tensor is non-contiguous, .view() fails. use .contiguous() to copy data into contiguous storage.
Broadcasting is “Virtual” Memory
broadcasting uses strides to repeat data without copying.
take a vector v, shape (1, 3), storage: , strides: (3, 1).
to broadcast to shape (4, 3), pytorch creates a view:
shape: (4, 3), strides: (0, 1).
analyze stride 0:
offset = (i0 × s0) + (i1 × s1)
for row 0: offset = (0 × 0) + (0 × 1) = 0 (value: 10)
for row 3: offset = (3 × 0) + (0 × 1) = 0 (value: 10)
stride 0 means moving along axis 0 doesn’t advance the pointer. the tensor appears to have 4 rows, but it re-reads the same row.
mental model: broadcasting isn’t copying or stretching—set stride to 0 to freeze the pointer for that axis.
checking if two tensors are compatible for brodcasting
step1 —> keep their dimensions vertically stacked
for each verticle stacked dimension check if either they are equal, one of them is one, or does not exist
if either of this is voilated we can not do brodcasting
for exmaple
1 3 2
2
matches
1 3 2
1 2 3
does nto match
3 1 2
4 2
yes matches
one more way
scenario a: original (5, 6)
target: (5, 6, 10)
input: (5, 6)
alignment:
ax-3 ax-2 ax-1
tgt: 5 6 10
inp: 5 6
result: crash. ax-1: 10 vs 6. mismatch.
scenario b: reshaped (5, 6, 1)
target: (5, 6, 10)
input: (5, 6, 1)
alignment:
ax-3 ax-2 ax-1
tgt: 5 6 10
inp: 5 6 1
result: compatible. ax-1: 10 vs 1. expansion.
you can also broadcast a scalar you know how so I wont go into depths of that
the element-wise product (hadamard product)
symbol: * or torch.mul()
logic: pure broadcasting.
rule: align dimensions right-to-left. 1s expand. multiply cell-by-cell.
result shape: max size at each dimension.
example: (3, 4) * (3, 4) → (3, 4)
c(i,j) = a(i,j) × b(i,j)
the matrix product (matmul)
symbol: @ or torch.matmul()
logic: linear algebra + broadcasting.
rule: split dimensions into batch (all except last two) and matrix (last two).
step 1: matrix compatibility
a: (..., n, k)
b: (..., k, m)
inner dimension k must match. result: (n, m)
step 2: batch compatibility
broadcast remaining dimensions (right-to-left, 1s expand).
example:
a: (3, 4), b: (4, 5)
a * b → error (4 vs 5)
a @ b → (3, 5)
high-dimensional matmul:
a: (10, 1, 3, 4)
b: (1, 20, 4, 5)
matrix core: (3, 4) @ (4, 5) → (3, 5)
batch: (10, 1) and (1, 20) → broadcast to (10, 20)
final shape: (10, 20, 3, 5)
note :- we can not multile 10,3,5 to 10,1,8
case a: vector @ matrix
vector v: (4,)
matrix m: (4, 5)
hidden process:
prepend 1: v becomes (1, 4)
multiply: (1, 4) @ (4, 5) → (1, 5)
squeeze: remove 1 → (5,)
case b: matrix @ vector
matrix m: (3, 4)
vector v: (4,)
hidden process:
append 1: v becomes (4, 1)
multiply: (3, 4) @ (4, 1) → (3, 1)
squeeze: remove 1 → (3,)
broadcasting is automatic shape manipulation. for manual geometry changes, use view, reshape, and permute.
permute(*dims): swaps axes. changes stride order, not data. result is usually non-contiguous. example: (a, b, c) → (c, a, b). you can say this is generalized version of transpose
view(*shape): reshapes tensor without copying data. only works on contiguous tensors. fails if memory is scrambled (e.g. after permute).
reshape(*shape): like view, but if tensor is non-contiguous, silently copies data to make it contiguous first. always works, but may be slower.
unsqueeze(dim): adds a dimension of size 1 at the specified axis. pure metadata operation—no data copied. used for explicit alignment, e.g., (3,) → (3, 1).
squeeze(dim=None): removes dimensions of size 1. if dim given, only removes that axis if size is 1. otherwise, removes all singleton dimensions. also a metadata-only operation.
expand(*shape): manually expands dimensions of size 1 to larger sizes, using stride 0—no data copied. new shape must match or expand from original, and only 1s can be expanded. expands are views, not copies.
expand vs repeat: expand is virtual (stride 0), repeat is physical (copies data).